
(This post concludes a series that begins here.)
Why is defining confidence so hard?
We all understand the idea of analytical confidence. Analyst and non-analyst alike, we have a clear sense that some probabilistic judgements are dodgy - rough guesses, stabs-in-the-dark, first impressions, better than nothing but not by much - while others are gold-standard - well-evidenced, based on robust modelling, the judgements of experts, the results of controlled experiments with solid protocols. We also feel like this distinction is important - legally, perhaps, with regard to situations such as the L'Aquila earthquake - but also morally, connected to the concept of 'epistemic responsibility', the notion that we ought to exercise diligence in ensuring our beliefs are justified and that it is wrong to make decisions based on dubious evidential foundations.
Given the force of our intuition regarding confidence, why does it seem so hard for us to say what 'confidence' actually means? And if it's important for decision-making, how then can we communicate our sense of confidence in anything other than vague, circular, and possibly incoherent terms?
Theories of confidence
We identified seven theories, each of which provides an alternative interpretation of the concept of confidence. For each theory, we looked at three factors: how coherent it was, how much it accorded with analysts' usage, and whether it was relevant to a decision (and therefore whether it was worth communicating without redundancy). The conclusions are summarised in the table below.
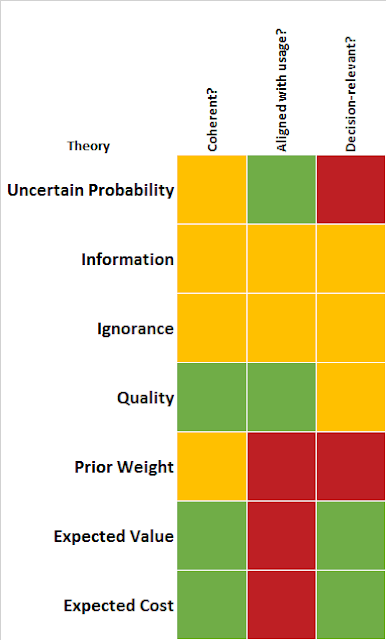
One salient feature is that none of the theories gets top marks on all three criteria. The theories that are both coherent and decision-relevant - those that relate to the expected value and expected cost of new information - are not ones that analysts themselves subscribe to. The 'quality' theory, which suggests that confidence relates to the general soundness of the available information, looks the best overall but it is only tangentially decision-relevant. We are faced with two problems that may have different answers: what does 'confidence' mean, and what should 'confidence' mean? In order to answer them we need to take a short philosophical detour. First, we'll look at why we may not be able to trust intuition and usage as a guide to finding a coherent definition of 'confidence'.
Naive realism
Naive realism is the approach to understanding the world that we are born with. We open our eyes, and the world is just there - we experience it directly, and what we experience is how it actually is. It is only through philosophical and scientific investigation that we find the demarcation between 'us' and 'the world' is fuzzier than it first appears. Our ability to perceive things at all depends on complex cognitive software, and some of the elements of our experience, such as the differences between colours, represent features that despite having significance in our evolutionary environment, do not form a qualitative distinction from a physics standpoint. Red things and green things are different, but the redness and the greenness, if it can be said to be anywhere, is in us. Our natural inclination, though, is to perceive the redness and greenness as 'out there', as a property of the world that we are merely passively perceiving. But the idea that 'redness' and 'greenness' are properties of things is not as coherent a theory as the idea that 'redness' and 'greenness' are instead properties of the way that we and things interact.
Our 'default setting' of naive realism may also apply to our concepts of probability and confidence. The view that probability is 'out there' is an intuitive one, as we saw when looking at the 'uncertain probability' theory of confidence, but it doesn't survive careful examination. It may be the same with 'confidence' itself. We might intuitively believe that confidence statements are statements about the system we're looking at, but this doesn't mean that a coherent theory can be made along these lines. Confidence might instead be better explained as a feature of us - of the payoffs from our decisions, or our personal information-set. Intuition cannot be relied on as a guide to what drives our intuitive sense of confidence.
Could our sense of 'confidence' be innate?
Questions of confidence generate strong and consistent intuitive responses, but as we've seen, the drivers of those responses are opaque to us. This is a clue that the notion of 'confidence' might be something rather fundamental for which we have evolved specialised computational software. By analogy, we have evolved to see red things as distinct from green things. As eye users, we don't need to know that the distinction in fact corresponds to differences in photic wavelengths. It is experienced as fundamental. This is because the distinction is so useful - for, say, finding fruit or spotting dangerous animals - that evolution has shaped our cognitive hardware around the distinction. The problem-space - the evolutionary environment and the decisions we need to make within it - has shaped our perception of the world, so animals with different problems see the world differently.
But how can ascription of analytical confidence possibly correspond to any problem faced by ancestral creatures? Isn't the application of a confidence judgement to a probabilistic statement an extremely-artificial, rarefied kind of problem, faced by desk-bound analysts but surely not by tree-dwelling primates?
Well, perhaps not. There's no reason to believe that ancestral primates played cricket, but the skills involved - motor control, perception, throwing projectiles - all have plausible mappings to the evolutionary environment. If there is a common theme to the foregoing discussions about confidence, it is one that relates to the justification for a decision: the extent to which we should act on the information, rather than continuing to refine our judgements. This certainly is a fundamental problem, one faced not just by humans but by all animals and indeed systems in general that need to interact with their environment.
The universal analytical problem
James Schlesinger
"Seldom if ever does anyone ask if a further reduction
in uncertainty, however small, is worth the cost..."
Other than in the most simplistic environments, animals do not face the kind of static decision-problems, with a fixed information set, that decision-theory primers tend to focus on. For most organisms, information is a flow that both affects and is affected by their behaviour. There is usually a tension between gathering information and acting on it. Collecting information is normally risky, costly and time-consuming. But the benefit of more information is reduced decision-risk. This means there is a practical engineering trade-off to be made, and one that is expressible in a simple question: "when do I stop collecting information, and act on it?"
Even in very simplistic models, 'solving' this trade-off - finding the optimal level of information - is often mathematically intractable (because probability has a broadly linear impact on payoffs but is affected logarithmically by information). Our response to dynamic information problems is therefore likely to be heuristic in nature, and could well depend on ancient cognitive architecture.
This means that if confidence is (as seems likely) something to do with the relative justifications for 'act now' versus 'wait and see', then it is entirely plausible that in making confidence judgements we are using the same cognitive machinery that we might use to, for example, decide whether to continue eating an unfamiliar fruit, to keep fishing in a particular stream, to make camp here or press on to the next valley, to go deeper into the cave, to hide in the grass or pounce. However it is experienced, optimal decision-making must involve consideration of the relative value, and relative cost, of further information-gathering, and of the risks associated with accepting our current level of uncertainty and acting now. A theoretical description of optimal decision-making in a dynamic information environment will utilise exactly these concepts, and so it shouldn't be surprising if we have cognitive software that appears to take them into account. Whether or not this is where our notion of 'confidence' comes from can only be a guess, but it's a satisfying theory with a robust theoretical foundation.
Should our definition of confidence capture intuition, or replace it?
Broadly speaking, there is a significant gulf between our intuitive concepts of probability and confidence, and what we might consider a coherent theoretical treatment of them. Crudely, we tend to think of probability as inherent in systems, whereas it is more-coherently thought of as a property of evidence. But we tend to see 'confidence' as a feature of the evidence - of its quantity or quality, say - whereas it might more-coherently be thought of as a function of the evidence we don't (yet) have, and plausibly of the importance of the decision that it informs. What, then, should we do in designing a metric for capturing confidence, and communicating it to customers?
This is not by any means a unique problem. Many precise concepts start out pre-scientifically as messy and intuitive. In time, they are replaced by neater, more-coherent concepts that are then capable of supplanting and contradicting our naive beliefs. Through such a process, we now say that graphite and diamond are the same thing, that whales are mammals, that radiant heat and light are degrees on a scale, that Pluto is not a planet and so on.

Photo: Steve Johnson
A similar thing has happened to the concept of probability. Seventeenth-century attempts to quantify uncertainty wrestled with the mathematical laws governing the outcomes of games of chance, but over several centuries these have been refined into a small but powerful set of axioms that have little superficial relevance to games involving dice and playing cards. The interpretation of probability has undergone a parallel journey, from the 'intuitive' concept that uncertainty resides in (for example) dice and coins, to the more-coherent notion that it is a feature of information. The intuition is a stepping-stone on the path to scientific precision.
How shall we define 'confidence'?
Over the course of the last few posts, we've reviewed a number of proposed systems for defining confidence. Mostly these are theoretically-weak, and often simply provide an audit trail for a probability rather than delineating a separate, orthogonal concept of the kind that we strongly believe 'confidence' must consist of. But they have intuitive appeal, probably because they were designed and drafted by working analysts rather than by information theorists. We have a choice to make, roughly between the following definitions:
Confidence-I: 'Confidence' measures the quality and quantity of the information available when the probabilistic judgement was formed. High-confidence probabilistic judgements will be founded on large bodies of evidence, repeatable experiments, direct experience, or extensive expertise. Low-confidence probabilistic judgements will be founded on only cursory evidence, anecdotes, indirect reports, or limited expertise.
Confidence-II: 'Confidence' captures the expected value of further information. High-confidence probabilistic judgements are associated with a high cost of information-collection, low-risk decisions, or low levels of uncertainty. Low-confidence probabilistic judgements are associated with a low cost of information-collection, high-risk decisions or high levels of uncertainty.
'Confidence-I' is easy for analysts to understand and to apply. But it adds little to what is already captured in the probability, and it doesn't directly tell the reader what they should do with the information. 'Confidence-II' will make little sense to most analysts, and will require training, and the development of robust heuristics, to understand and apply. But it says something meaningfully distinct from the probability of the judgement to which it applies, and carries the immanent implication that low-confidence judgements ought to be refined further while high-confidence ones can be acted on.
We hope that this series of posts has demonstrated a number of things: that 'confidence' is an important concept distinct from probability, that intuition is not a reliable guide as to its meaning, and that it can be made meaningful but only counter-intuitively. Is an attempt to move towards a meaningful Confidence-II-type definition worth the cost? Will it add more than the effort of getting there? To an analytical organisation with enough vision, capability, and commitment to rigour, perhaps it would at least be worth experimenting with.