
(This is part 5 of a series of posts about probability and confidence that starts here.)
In the last post, we outlined the seven theories that have been put forward as candidates for what we mean when we talk about confidence in an analytical judgement. In this post, we'll look at the first theory - the 'Uncertain Probability' theory. This is the idea that there is a 'correct' probability, but that we might be unsure about its value. The more certain we are about the 'true' value, the higher our confidence will be. It's an intuitively-appealing theory that a significant proportion of survey respondents offered as a proposed interpretation. But it rests on a number of potentially-tricky suppositions.
As with all these theories, we'll apply three tests: internal coherence, alignment with usage, and decision relevance.
Is the theory internally coherent?
If the 'uncertain probability' theory is correct, probability is a kind of quantity about which it's meaningful to be uncertain. This has prima facie plausibility. Being uncertain about numbers happens all the time. You're probably fairly certain about your own age - your confidence in the estimate is quite high. But you'd be less certain about the age of someone you'd just met - you could give a point estimate, but you'd probably be happier giving a plausible range, say 35-45. If you were asked about the age of someone about whom you knew nothing other than their name, your range would be wider still. A probability is also a number, like someone's age - so why couldn't you express uncertainty about probability in the same way?
The problem is that if probability is a quantity of something, which we can measure to a higher or lower level of accuracy, it is one with some very strange properties. First, the 'correct' probability of a hypothesis seems to vary between people. If I've just tossed a coin, and looked at it, I know the probability of heads is either 0% or 100%. But if I haven't shown it to you or indicated the results in any way, you will quite rightly put a probability of 50% on that hypothesis. It's the same coin, but our probabilities are different.
Probability can also vary over time in ways that don't seem to involve the subject of the hypothesis changing in any way. Before the Curiosity Rover measured radiation levels en route to and on Mars, scientists could only put probabilities on whether these would be at acceptable levels to permit a manned mission. Now we know that radiation exposure would be at the lower end of what was expected, we're more certain that the risk would be acceptable. Radiation levels haven't changed - but the probabilities we attach to them have.
What these examples suggest is that probability is not a feature of the world per se, or at least is not an objective feature of the subject of the hypothesis. The probability of a coin coming up heads isn't in the coin somewhere, and the probability of radiation levels for a trip to Mars being prohibitively dangerous didn't change because something to do with space radiation changed. If probability isn't a quantity 'out there' that we're measuring, what is it?
Where is the 50% probability of heads?
Information
The element here that explains differences between probabilities - between people, or over time - is information. In the case of the coin, I had full information about it whereas you had no information. In the case of the Martian radiation, it was new information - not a change in the system per se - that made us revise our probability that a trip there would pose an acceptable radiation risk.
It's this insight - that probability and information are interrelated - that led to the development of 'information theory'. While working at Bell Labs in 1945, the mathematician Claude Shannon put forward the idea that probability could be used to quantify information. In doing so, he created a field of mathematics that underlies a vast range of phenomena and technology, including much of modern computing.
Under Shannon's approach, information is not simply related to probability - it's not 'one of the things' that affects our probability estimates - but is actually measured using it. 'Shannon entropy' - a measure of the 'information content' of a piece of evidence - is defined in terms of the probability of receiving one of a number of possible 'signals'. The maths of information theory are too involved to cover here, but they do have an intuitive component. The key insight is that unusual or unexpected evidence will contain more information than unsurprising evidence, because it eliminates more possibilities.
Delware: officially more surprising than California
For example, let’s say you’re interested in someone’s home address, and all you know is that they live somewhere in the US. You start by asking which state they live in. Before they answer, you know that it’s more likely they’ll say ‘California’, with its 38 million denizens, than ‘Delaware’, which has less than 1 million. For this exact reason, if they do actually live in Delaware, this will eliminate more possible addresses than if they live in California. ‘I live in Delaware’ is therefore a message with more information in it than ‘I live in California’. Shannon’s measure of information, which denominates it in ‘bits’, captures this insight in a precise mathematical way.
What this implies, among many things, is that 'probability' isn't a thing 'out there' that we're trying to measure, as with other quantities; instead, probability is a thing 'in here' that summarises everything we know about a hypothesis. And so the concept of being uncertain about it is not easy to make work. There's no 'gap' between us and the information we have about a hypothesis (and therefore its probability) that could explain where the uncertainty could arise. And if we are tempted to say 'I'm not sure how much information I have' - well, this is strictly the same as having less information, because it means that there are a wider range of plausible hypotheses about how the evidence in front of us could have arisen.
Having said all this, there have been some attempts to put the idea of 'uncertain probability' into action. One of them is the system developed by Dempster and Shafer, which incorporates imprecise probability estimates. Another is the idea of 'Knightian Uncertainty', proposed by Frank Knight in 1921, which seeks to draw a distinction between 'measurable' and 'unmeasurable' uncertainty. Some have also advanced pragmatic grounds for expressing uncertainty about probability - because, for example, it discourages overconfidence in models, or because it is harder for non-specialist audiences to misinterpret. However, it is fair to say that these approaches are not widely accepted by most probability theorists; an outline of them can be found here, and the comment thread gives a worthy sense of the debate about them.
The Frequentist Switcheroo
One particular interpretation of probability that sees it as a measurable feature of the world is 'frequentism', and it's important enough to merit special treatment here. Frequentism is the view that 'probability' can be equated with - i.e. is the same thing as - the frequency of an outcome in the 'long run'. The main alternative interpretation of probability is the Bayesian view, which is broadly the one set out above that 'probability' measures your available information. Although frequentism became the dominant statistical approach in the early half of the last century, in the last few decades it's been largely driven out of polite society by the Bayesian interpretation. Not only is the Bayesian view almost certainly more coherent than frequentism (for the reasons set out above), it's also far more useful.
One question in our survey was designed specifically to capture analysts' attachment to the frequentist way of thinking. It was a fairly abstract question that put analysts in the following scenario:
"A box in front of you contains a large number of black balls and white balls, but you don’t know what their relative proportions are and you can’t look into the box. You have been asked to state the probability of the next ball being black. The information you have suggests the answer is 50%."
Analysts were then asked about how confident they'd be in the statement: "The probability of a black ball being drawn next is 50%" in four cases. In the first case, no balls had been drawn from the box. In the second case, two balls had already been drawn (with replacement). In the third, ten balls had been drawn, and in the fourth, one hundred balls had been drawn (again, with replacement). Importantly, in every case, exactly half of the balls were black. And, in this question, analysts' responses were very strongly correlated with the number of balls drawn:
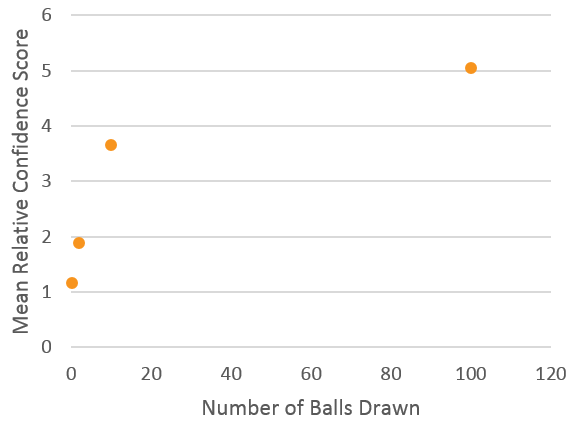
This suggests that in the context of this question at least, analysts are applying a 'frequentist' interpretation of probability, and surreptitiously substituting a different question for the one they were asked. The question is about the following proposition:
A: The probability that the next ball will be black is 50%
and not:
B: Half the balls in the box are black
To hardcore frequentists, (B) is the same as (A). To a Bayesian, they're very different: drawing increasing numbers of balls, assuming they are half black and half white, is evidence supporting B, but it does nothing for A, which is the proposition we actually care about in this scenario.
Frequentism is problematic for all sorts of reasons, and the debate between frequentists and Bayesians is so well-trodden that we won't cover it in detail here. A non-technical attack on frequentism can be found here. But even if these views are wrong, and frequentism can be made coherent, for most analysts there is a much more significant obstacle to using a frequentist interpretation of probability, which is that it massively restricts the scope of probability in a way that would make it practically impossible to use.
The reason the frequentist interpretation is unsustainable for most real-world analysis is that it implies that statements like "climate change is almost certainly linked to CO2 emissions", "further Russian encroachment in Ukraine is unlikely", or "the new engine design will probably improve efficiency by around 2%" are literally meaningless. Because these are not repeatable experiments, words like 'almost certainly', 'unlikely' and 'probably' can't be given any interpretation at all. If you think these statements do mean something then you're almost certainly not a frequentist. (Of course, if you are a frequentist then that last statement is meaningless too.) So while their responses to the 'balls in a box' question might be coherent under a frequentist interpretation, the 'some analysts are frequentists' theory doesn't account for their reaction in these more-realistic kinds of scenario.
Summary
There are good grounds for thinking that the 'uncertain probability' theory is incoherent. Nevertheless, it would be unfair to present this as an entirely uncontroversial conclusion. The debate here is not about probability per se: the laws of probability have been accepted mathematically for several centuries, and their formalisation by Kolmogorov in 1933 has not been seriously challenged. What we are investigating here is instead the interpretation of probability - what probabilities actually mean. Under the Bayesian interpretation, uncertainty about probability is incoherent. Under the frequentist interpretation - which is itself considered incoherent by most specialists - uncertainty about probability is possible, but only under very restricted circumstances involving repeatable experiments. So uncertainty about probability is either an incoherent idea, or it's applicable to such a narrow range of situations that it cannot account for confidence statements in most analytical circumstances.
Does the theory align with usage?
Despite being difficult to make coherent, many analysts think of their own confidence statements as expressing uncertainty about probability. Here are some of the responses from Aleph Insights' survey of analysts and their customers in late 2014:
"Confidence here (as I've used it) is an expression of my imprecise range would be for the stated probability as a odds for a fair bet (odds I'd be equally willing to accept to bet for or against)"
"How sure you are about your assessment. It could be thought of as a probability on a probability. i.e. how likely is it that your probability estimate corresponds to the true probability?"
"An expression of the range of expected answers (25% to 75% probability?) compared to my predicted answer - the narrower the range, the greater the confidence..."
In summary, many analysts do indeed have in mind something like 'certainty about the true probability' when expressing confidence about judgements.
Decision-relevance
The final test to which we will put the 'uncertain probability' theory is that of decision-relevance. If uncertain probabilities were a thing, would they be relevant to a decision-maker? In other words, is there some feature of a certain probability that will be different to that of an uncertain probability, of which we should take account?
The answer, regardless of which interpretation of probability one subscribes to, is 'no'. There are several ways of reaching this conclusion. In terms of observable outcomes, the properties of an 'uncertain probability' are entirely identical to those of a certain probability equal to its expected value. For example, let's suppose you have a coin that's certainly 50% likely to come up heads; by definition this will come up heads 50% of the time. Now let's suppose you select one of two coins at random: one comes up heads 60% of the time, and the other comes up heads 40% of the time. This time, the probability of heads is 'more uncertain'. (The scare quotes are here because, as we said above, this idea is probably incoherent.) Now, the probability of heads is... still 50% (50% x 40% + 50% x 60%). So in each case, you will toss a head exactly half the time. Any reason to take a course of action based on this probability will have exactly the same force in both circumstances.
We can take a more intuitive approach. There are two boxes in front of you, and you will randomly select one and choose a ball from it. The first time you perform the experiment, both boxes have two white balls and two black balls. The second time you perform the experiment, one box has three black balls and one white ball, and the other has one black ball and three white balls:
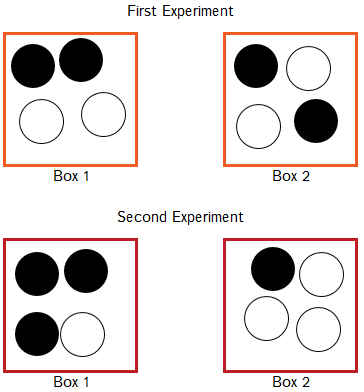
The first experiment seems to have a 'certain' probability of a black ball - 50%. The second experiment seems to have an 'uncertain' probability - either 25% or 75%. But crucially, in each experiment, we are choosing from eight possible balls, half of which are black and half of which are white. Our sense that one has a 'certain' probability, and the other an 'uncertain' one does not, in fact, have any material bearing on any properties of the outcome, including the expected value of any decisions whose return depends in some way on that outcome.
In Summary

The 'uncertain probability' theory of confidence is probably incoherent, although it does accord with some analysts' usage. It is not decision-relevant, so if it is true, there is no need to communicate confidence to customers.
In the next post, we'll look at the next two ideas: the 'Information' and 'Ignorance' theories of confidence.